Big data analytics emerged as a requisite for the success of business and technology. That is why we now have various big data frameworks in the market to choose from. Apache Spark and Hadoop are two of such big data frameworks, popular due to their efficiency and applications. While we do have a choice, picking up the right one has become quite difficult. Perhaps, performing a downright comparison of the pros and cons of these tools would be no good as well, since this will not highlight the particular usefulness of a tool. Instead, this article performs a detailed Apache Spark vs Hadoop MapReduce comparison, highlighting their performance, architecture, and use cases.
Before delving into a detailed comparison, we will briefly explore what Spark and Hadoop are.
Let’s start exploring the frameworks.
What is Apache Spark
Apache Spark is a real-time data analytics framework that mainly executes in-memory computations in a distributed environment. It offers incredible processing speed, making it desirable for everyone interested in big data analytics. Spark can either work as a stand-alone tool or can be associated with Hadoop YARN. Since it flaunts faster data processing, it is suitable for repeated processing of data sets. Nonetheless, it requires more power.
What is MapReduce, or Hadoop MapReduce
MapReduce is what constitutes the core of Apache Hadoop, which is an open source framework. The MapReduce programming model lets Hadoop first store and then process big data in a distributed computing environment. This makes it capable of processing large data sets, particularly when RAM is less than data. Hadoop does not have the speed of Spark, so it works best for economical operations not requiring immediate results.
Hadoop MapReduce vs Spark – Detailed Comparison
Both Spark and Hadoop serve as big data frameworks, seemingly fulfilling the same purposes. However, they have several differences in the way they approach data processing. Here, we draw a comparison of the two from various viewpoints.
Spark vs MapReduce Performance
At a glance, anyone can randomly label Spark a winner considering the data processing speed. Nonetheless, delving into the details of the performance of Hadoop and Spark reveals more facts.

Spark vs Hadoop big data analytics visualisation
Apache Spark Performance
As said above, Spark is faster than Hadoop. This is because of its in-memory processing of the data, which makes it suitable for real-time analysis. Nonetheless, it requires a lot of memory since it involves caching until the completion of a process. So, if the data fits well into memory, Spark can become the right option.
MapReduce Performance
Hadoop processes data by first storing it across a distributed environment, and then processing it in parallel. The software is basically designed to process data gathered from various sources. Thus, it takes quite some time to show results. In other words, Hadoop should not be considered for data processing where faster results are needed.
However, if speed and time are not critical, then Hadoop outperforms Spark Apache as it conveniently handles large data sets, is capable of handling hardware failures, and does not require a lot of processing memory. Besides, unlike Spark, it does not require caching, thus saving up memory.
Hadoop vs Apache Spark Language
Hadoop MapReduce and Spark not only differ in performance but are also written in different languages. Hadoop is usually written in Java that supports MapReduce functionalities. Nonetheless, Python may also be used if required.
On the other hand, Apache Spark is mainly written in Scala. But, it also comes with APIs for Java, Python, R, and SQL. Hence, it offers more options to the developers.
Spark and MapReduce Architecture
Spark and MapReduce both perform data analytics in a distributed computing environment. However, both the software process a given dataset differently. Below we explain and compare the architecture when it comes to Spark vs MapReduce.
Apache Spark Architecture
Spark is a clustered computing system that has RDD (Resilient Distributed Dataset) as its fundamental data structure. This data structure makes Spark resilient to faults and failure when processing data distributed over multiple nodes and managing partitioned datasets of values. It is RDD’s capability to exploit the power of multiple nodes in a cluster that makes it faster and tolerant to faults.
While executing data analysis, Spark Apache manages the distribution of datasets over various nodes in a cluster, creating RDDs. RDD is an immutable collection of objects that may be lazily transformed via Directed Acyclic Graph (DAG). Each dataset in an RDD is divided into multiple logical partitions facilitating in parallel computation across different nodes in the cluster.
Inside the cluster, the master node holds the driver program where the Spark Context is created for smooth execution of all Spark functionalities. The Spark Context collaborates with the Cluster Manager to manage a task. Besides, the Spark architecture also consists of Worker Nodes that hold data cache, perform task execution, and return the results to the Spark Context. The number of Worker Nodes may be increased as desired for faster processing. However, it will require more space.
Apache Spark Architecture Diagram
The following diagram illustrates Spark architecture. Whenever an RDD is created in the Spark Context, it is then further distributed to the Worker Nodes for task execution alongside caching. The Worker Nodes, after task execution, send the results back to the Spark Context.
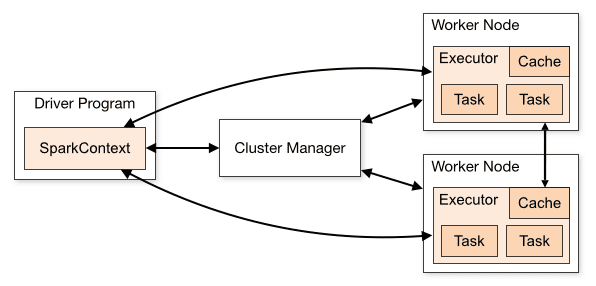
Apache Spark architecture
Hadoop MapReduce Architecture
Hadoop comprises of two core components – HDFS (Hadoop Distributed File System) and YARN (Yet Another Resource Negotiator). As the name implies, HDFS manages big data storage across multiple nodes; while YARN manages processing tasks by resource allocation and job scheduling.
The HDFS architecture is based on two main nodes – a NameNode, and multiple DataNodes. These nodes exhibit a master/slave architecture where a NameNode serves as the master managing storage and logging changes to the metadata of all files in a cluster. While the DataNodes are the slave nodes that perform NameNode’s commands.
YARN also comprises of two major components that manage the core functions of resource management and task scheduling. These are the Resource Manager and the Node Managers. Resource Manager is a cluster-level component (there can only be one per cluster), whereas Node Managers exist at the node level, making up several NodeManagers in a cluster.
Hadoop MapReduce Diagram
The following diagram shows the architecture of Hadoop HDFS. The NameNode saves the metadata of all stored files as well as logs any changes to the metadata. Whereas, the DataNodes store the actual data, attend read/write requests and performs NameNode’s instructions regarding creation, deletion, or replication of blocks.
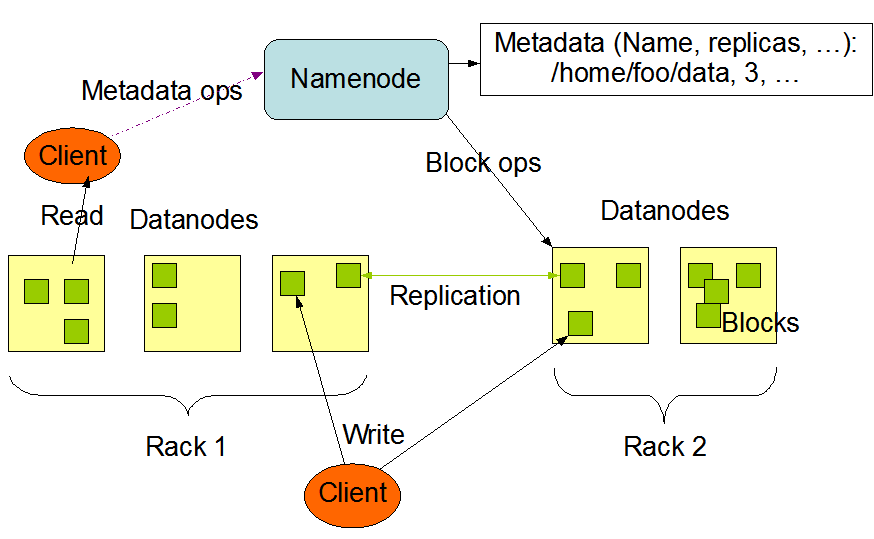
Hadoop HDFS architecture
In YARN architecture, the Resource Manager allocates resources for running apps in a cluster via Scheduler. Besides, its ApplicationManager component accepts job submissions and negotiates for app execution with the first container.
Node Managers manage containers and track resource utilization. NodeManagers also communicate with ResourceManager for updates.
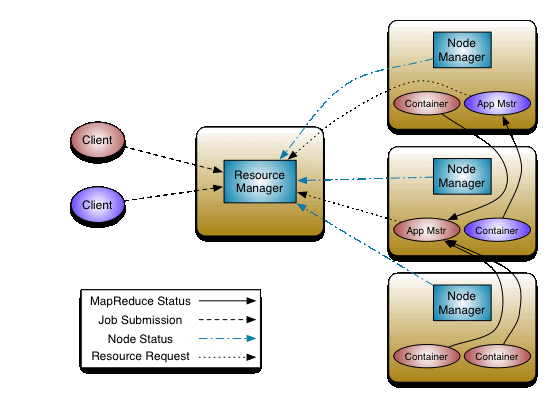
Hadoop YARN architecture
Hadoop vs Spark Cost
In general, both Hadoop and Spark are free open-source software. However, developing the associated infrastructure may entail software development costs. From the viewpoint of Hadoop vs Apache Spark budget, Hadoop seems a cost-effective means for data analytics. It requires less RAM and can even work on commodity hardware.
Spark, on the other hand, requires more RAM since it works faster and does not consume disk I/O. So, it may require pricey systems. However, as it boasts advanced technology, it requires less computation units, and this may lower the costs.
Spark vs MapReduce Compatibility
Spark and Hadoop MapReduce are identical in terms of compatibility. While both can work as stand-alone applications, one can also run Spark on top of Hadoop YARN. Spark also supports Hadoop InputFormat data sources, thus showing compatibility with almost all Hadoop-supported file formats.
Likewise, Hadoop can also be integrated with various tools like Sqoop and Flume.
Apache Spark And Hadoop Security
Spark supports authentication via shared secret. Its security features also include event logging, and it uses javax servlet filters for securing web user interface. Nevertheless, if it runs on YARN and integrates with HDFS, it may also leverage the potential of HDFS file permissions, Kerberos, and inter-node encryption.

On the other hand, Hadoop surpasses Apache Spark in terms of security, as it supports Kerberos authentication. While Kerberos may be difficult to handle, Hadoop also supports third-party authentication, such as Lightweight Directory Access Protocol (LDAP). It also offers conventional file permissions, encryption, and access control lists (ACLs). Besides, it ensures providing appropriate user permissions for a job with Service Level Authorization (SLA). Here, Hadoop surpasses Spark in terms of security features.
MapReduce Vs Spark Use Cases
While Apache Spark and Hadoop process big data in different ways, both the frameworks provide different benefits, and thus, have different use cases.
Apache Spark Use Cases
Spark, being the faster, is suitable for processes where quick results are needed. Hence, Spark fits best for:
- Real-time analysis of big data
- Fast data processing with immediate results
- Iterative operations
- Machine Learning algorithms
- Graph processing
Hadoop MapReduce Use Cases
As noted above, comparing processing speeds of Apache Spark vs MapReduce gives Spark an edge over Hadoop. However, Hadoop exhibits tremendous capability of processing large data sets. Hence, it works best for:
- Analysis of archive data
- Operations involving commodity hardware
- Data analysis where time factor is not essential
- Linear data processing of large datasets
Spark And Hadoop Examples
By comparing MapReduce vs Spark practical examples, one can easily get an idea of how these two giant frameworks are supporting big data analysis on large scale.
Apache Spark Examples
- Risk management and forecasting
- Industrial analysis of big data gathered from sensors for predictive maintenance of equipment
- Fraud detection and prevention with real-time analysis
- Delivering more tailored customer experiences by analyzing data related to customer behavioral patterns
- Predicting stock market trends with real-time predictive analysis of stock portfolio movements
MapReduce Examples
- Social networking platforms such as Facebook, Twitter, and LinkedIn use MapReduce for data analyses
- Law enforcement and security agencies use Hadoop for processing huge datasets of criminal activities gathered over a period of time for crime prevention
- Finance, telecom, and health sectors rely on Hadoop for periodic analysis of big data to fuel future operations based on the gather customer reviews
- Improvement of science research with data analysis
- Data analysis by city and state governments for improving overall infrastructure, such as by analyzing data related to traffic situations
Hadoop MapReduce Or Apache Spark – Which One Is Better?
Considering the overall Apache Spark benefits, many see the framework as a replacement for Hadoop. Perhaps, that’s the reason why we see an exponential increase in the popularity of Spark during the past few years.
Nonetheless, the outlined comparison clarifies that both Apache Spark and Hadoop have advantages and disadvantages. Though both frameworks are used for data processing, they have significant differences with regards to their approach to data analytics. Both of them are designed in different languages and have distinct use cases. Therefore, it purely depends on the users which one to choose based on their preferences and project requirements.